Results
Matches or beats gradient-based steering
Across simulation and hardware, PAINT meets or improves on Real-Time Chunking (RTC) on both task success and prefix consistency — while never touching the policy.
| Method | SR ↑ | ATR ↓ | CON ↓ |
|---|---|---|---|
| Block Stacking · single-arm | |||
| TE | 0.55 | 28.27 | – |
| RTC | 0.75 | 16.04 | 0.030 |
| PAINT | 0.75 | 15.32 | 0.023 |
| Toy in Drawer · single-arm | |||
| TE | 0.60 | 23.19 | – |
| RTC | 0.75 | 17.85 | 0.025 |
| PAINT | 0.85 | 17.08 | 0.023 |
| Banana in Pot · single-arm | |||
| TE | 0.60 | 29.57 | – |
| RTC | 0.70 | 30.15 | 0.031 |
| PAINT | 0.70 | 29.79 | 0.026 |
| Towel Flinging · bimanual | |||
| TE | 0.51 | 17.13 | – |
| RTC | 0.76 | 6.98 | 0.028 |
| PAINT | 0.79 | 7.44 | 0.023 |
| Shorts Folding · bimanual | |||
| TE | 0.90 | 33.82 | – |
| RTC | 0.90 | 18.79 | 0.027 |
| PAINT | 0.95 | 19.77 | 0.025 |
| Part Placing · humanoid | |||
| TE | 0.50 | 68.51 | – |
| RTC | 0.70 | 18.28 | 0.030 |
| PAINT | 0.70 | 17.32 | 0.021 |
PAINT (ours). Best value per task & metric in bold. 20 trials per method–task pair. TE is synchronous, so it has no CON score (—).
Simulated benchmark · Kinetix
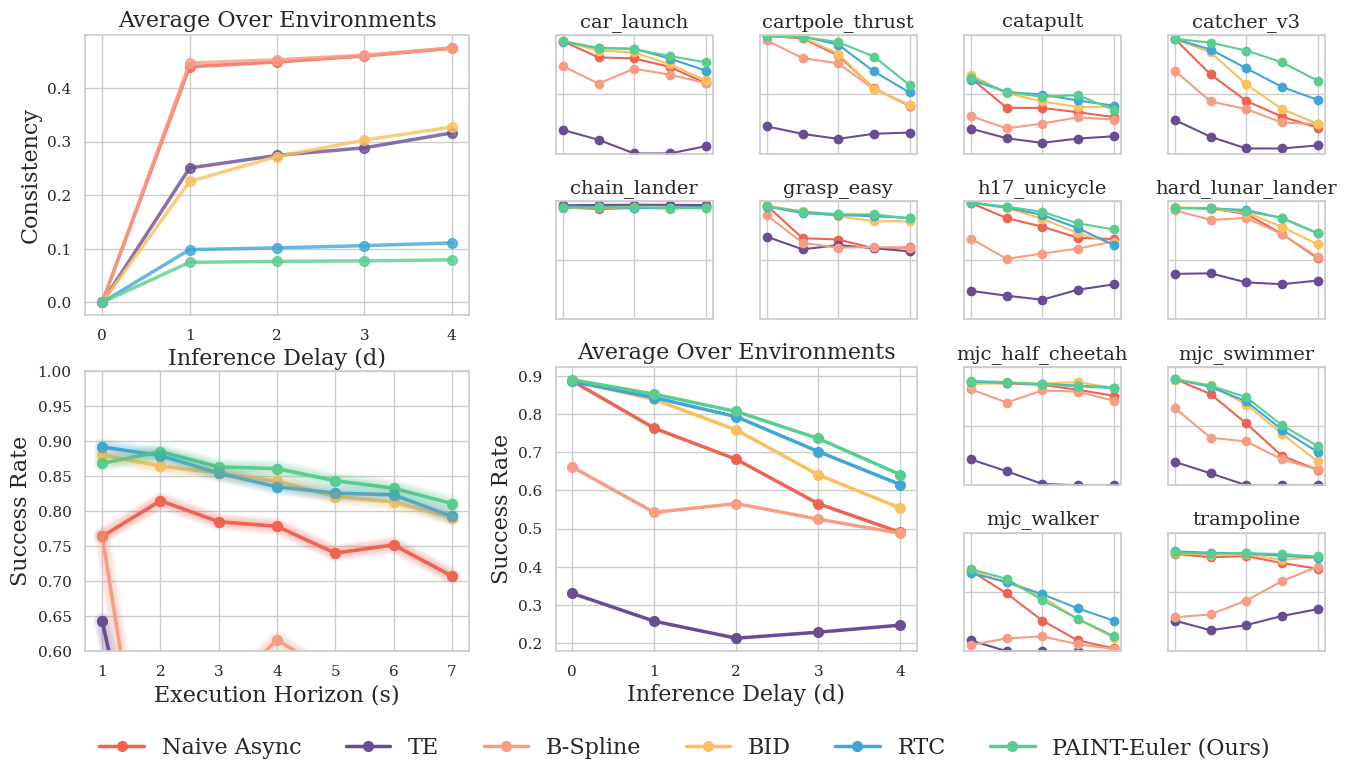
Across 12 force-control environments and rising inference delay, naive async degrades sharply while temporal ensembling and B-spline smoothing barely help — neither conditions on the executed prefix.
PAINT-Euler holds the strongest delay robustness and the lowest prefix mismatch, consistently above RTC — without any gradient computation. Each point aggregates 2,048 trials.
ablation Among inversion methods, backward Euler best balances quality and cost — on par with the 2× costlier DPM-Solver.
86 ±2 ms PAINT vs 113 ±3 ms RTC
Faster than gradient-based steering on smaller VLAs.
311 ±7 ms PAINT vs 213 ±4 ms RTC
The trade-off: extra forward passes replace backward ones.